AI advances with benchmarking - value models are the key to benchmarking business agents


Steven Forth is CEO of Ibbaka. Connect on LinkedIn
Advances in AI are measured by a set of well-established benchmarks. This goes back to 2009 and ImageNet, where teams competed to correctly classify more than 14 million images into 20,000 categories. The unexpected win by the deep learning system AlexNet in 2012, which trounced the competition, heralded the modern era in AI.

Standard Benchmarks for Large Language Models
Many benchmarks are now in place to measure the performance of Large Language Models. These range from measures of language understanding and reasoning to multilingual capabilities, conversational quality, and on and on.
Five of the top benchmarks…
MMLU-Pro (Massive Multitask Language Understanding - Pro)
Assesses general knowledge and reasoning across a wide range of academic and professional subjects, making it a comprehensive test of an LLM’s breadth and depth of understanding.
GPQA (Graduate-level Professional Question Answering)
Focuses on expert-level reasoning and factual accuracy using challenging, domain-expert-designed questions, providing a rigorous measure of advanced reasoning and specialized knowledge.
HumanEval
Evaluates code generation abilities, specifically functional correctness in Python programming tasks, and is the gold standard for measuring LLMs’ coding capabilities.
MATH
Tests mathematical problem-solving skills using high-school and competition-level math problems, requiring logical reasoning and step-by-step solutions.
BBH (Big Bench Hard)
Comprises a suite of challenging reasoning and language understanding tasks, correlating well with human preferences and pushing models to demonstrate advanced comprehension and reasoning.
Not surprisingly, there are websites that report on and analyze these metrics, such as LLM Stats and the Vellum LLM Leaderboard.
Holistic Assessment of LLM Agents Across Diverse Business Scenarios and Interactions
These general benchmarks are not specific enough to be used to evaluate the models for business applications. In May, Salesforce AI Research published an important article, “CRMArena-Pro: Holistic Assessment of LLM Agents Across Diverse Business Scenarios and Interactions.”
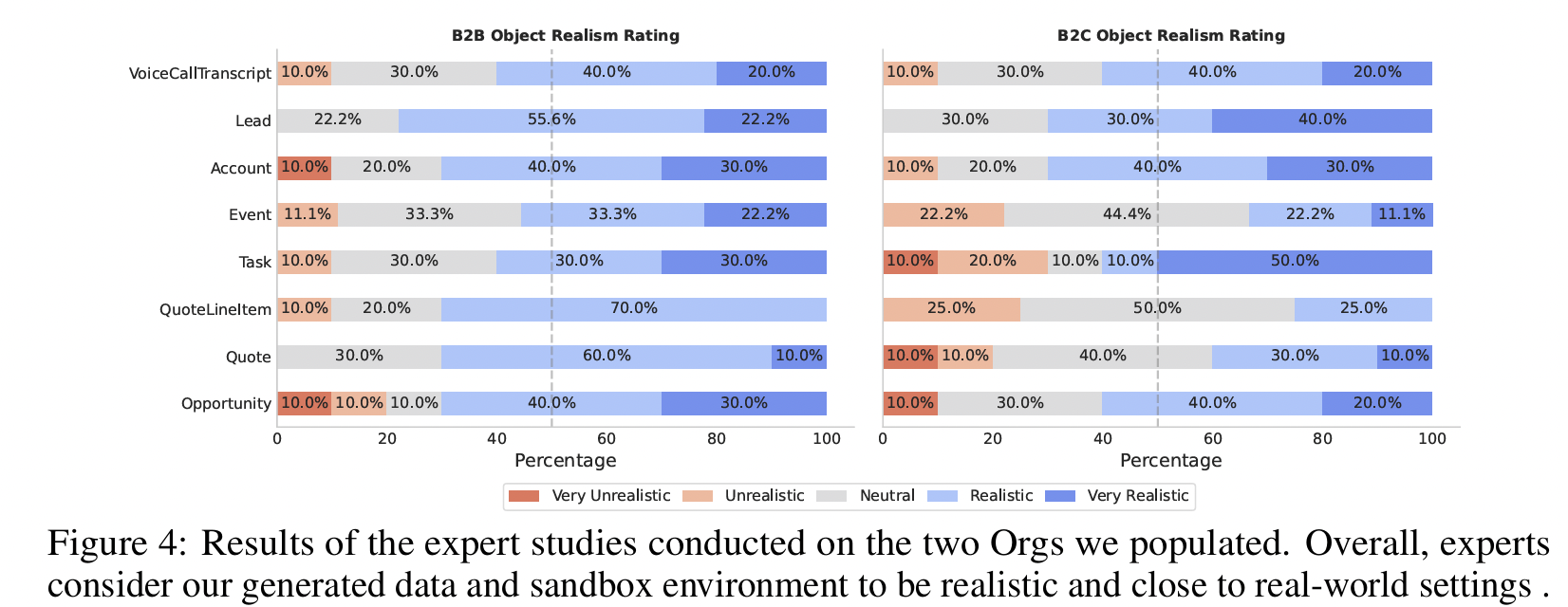
CRMArena-Pro, a novel benchmark for holistic, realistic assessment of LLM agents in diverse professional settings. CRMArena-Pro expands on CRMArena with nineteen expert-validated tasks across sales, service, and 'configure, price, and quote' processes, for both Business-to-Business and Business-to-Customer scenarios. … Experiments reveal leading LLM agents achieve only around 58% single-turn success on CRMArena-Pro, with performance dropping significantly to approximately 35% in multi-turn settings.
Key points from this research are as follows …
Performance Limitations
Leading LLM agents achieve only ~58% success in single-turn tasks and ~35% in multi-turn interactions. Ouch.
Workflow Execution is the most tractable skill (83%+ success), while skills like Database Querying, Textual Reasoning, and Policy Compliance remain challenging.
Confidentiality-Awareness Trade-offs
Agents exhibit near-zero inherent confidentiality awareness, risking sensitive data exposure.
Prompting improves confidentiality but often reduces task performance by 5–11%, creating a reliability-cost dilemma.
Cost Efficiency
Gemini-2.5-flash and Gemini-2.5-pro offer the best performance-cost balance.
High-cost models like GPT-4o show diminishing returns, impacting ROI for B2B deployments.
These are interesting initial results, and it will be important to see how performance improves (we hope) over time.
Benchmarking valueIQ
These benchmarks seem a bit too abstract for the AI agents being developed for Sales and Pricing applications. This is an area that Ibbaka is actively engaged in, and we expect to begin beta testing of our first agent, valueIQ, in the summer.
In developing valueIQ, we are doubling down on benchmarking.
valueIQ development is driven by three benchmarking frameworks:
Value Model - what makes for a good value model
Value Conversation - Does the coach help a salesperson understand and communicate the value to be provided to a customer
Sales Presentation - what makes for a good sales deck and value story
For each of these, there is an evaluation rubric and a prompt used to automate the benchmarking. Our initial standard is that valueIQ must score higher than ChatGPT Pro (the $200 per month version of ChatGPT).
Note how the benchmarking aligns with the different agents that power the valueIQ sales co-pilot.
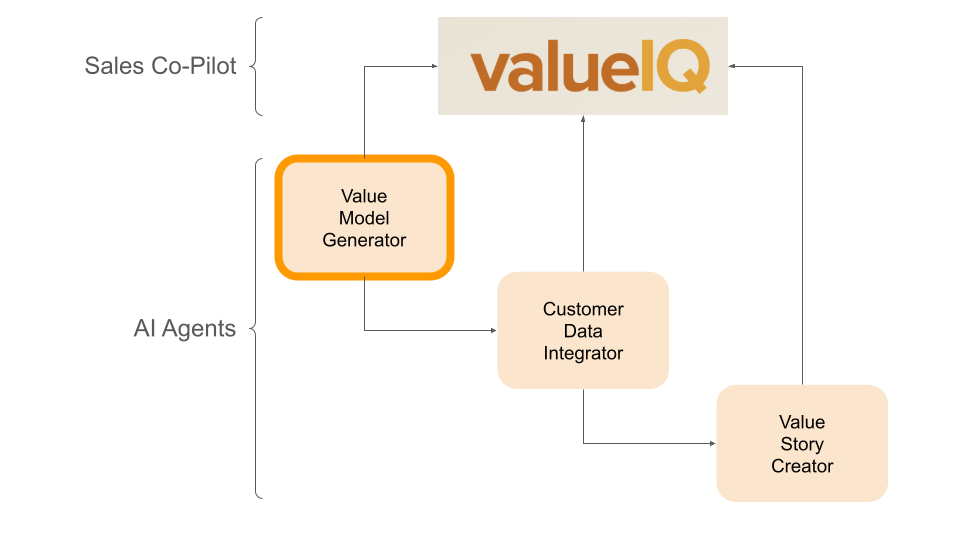
valueIQ agent architecture
Value Models as the Benchmark for Business AIs
Down the road, we see Value Models emerging as the standard benchmark for a business AI.
A Value Model is a formal system that represents how a product or solution creates value for a customer or customer segment relative to an alternative. It does this by quantifying and organizing the economic, emotional, and sometimes community value drivers into a structured framework, typically as a system of equations. Each equation (value driver) estimates a specific vector of value (such as increased revenue, reduced costs, or mitigated risk), making the value proposition tangible and measurable for both sellers and buyers.
This model enables organizations to clearly communicate, customize, and connect the value their offerings deliver, supporting value-based pricing, sales, and customer success strategies.
Value models can be generated for use cases and customers, and then different solutions benchmarked against the value model to see what drives value in a category. Ibbaka has begun to do this, in a preliminary way, in our Category Value Reports (three of which have been published so far).

☝️Join the valueIQ waitlist to embed value intelligence in your sales conversations.☝️
Navigating the new pricing environment brought by AI agents? Contact us @ info@ibbaka.com
