How to assess your pricing model


Steven Forth is CEO of Ibbaka. Connect on LinkedIn

Modern AI systems are driven by benchmarking. Every time a new foundation model is released it is quickly measured against standard benchmarks such as Massive Multitask Language Understanding (MMLU), Graduate-Level Google-Proof Q&A Benchmark (GPQA) and so on (see Benchmarking LLMs: A guide to AI model evaluation). This relentless benchmarking is one reason these models improve so quickly.
As generative AI infiltrates pricing design and optimization companies need to get better at benchmarking their pricing models. This will drive continuous improvement in pricing which can benefit both buyers and sellers. As a step towards this, Ibbaka has been working with Michael Mansard to develop a way to benchmark pricing models.
We introduced our approach on May 29, 2025, in our webinar. Let’s go a bit deeper into our approach. You can watch the webinar here.
The 12 Factor Benchmark for Pricing Models
After extensive analysis of what makes for a good pricing model, we came up with six categories and twelve factors to use in benchmarking a pricing model. This is designed for use with B2B SaaS and AI agents, but may be generally applicable.
These twelve factors have been tested across multiple scenarios to make sure that each factor is orthogonal (each factor can change independently of the other eleven factors) and relevant to business performance.

The 12 Factor Benchmark for Pricing Models (Ibbaka and Mansard, May 2025)
Value Alignment
Grows in the same direction as value delivery
Grows at the same speed as value delivery (= good proxy for value delivery)
Feasibility
Can be easily measured/accessed
Can be easily audited/proven (=not "cheated")
Acceptability
Is easily understood by your buyers (within the given ICP)
Is mutually accepted by you and your buyers (within the given ICP)
Attributability
Can create a clear linkage on why your solution optimizes the metric (=not perceived as a quasi-"tax")
Can be defended over time, should the delivered value remain the same - i.e. do not become "table stakes" (e.g. % savings or any types of industrial ratios)
Predictability
Can be forecasted against on your and your customer's ends
Can eventually lead to some level of commitment
Customer-centricity
Promotes more utilization (=not penalizing for growth)
Creates positive differentiation versus alternatives and competitors
Profitability
Scales with costs
Maintains the relationship Value > Price > Cost
For deeper context, see Michael Mansard’s recent article, The ‘COMPASS’ Agentic AI Pricing Metric framework: Your 2-Part Monetization Survival Guide to the Autonomous Age.
Assessing Pricing Models using the Twelve Factor Benchmark
Generative AI can be used to provide an independent assessment of a pricing model. When assessing a pricing model, it is important to do so from both the vendor’s perspective and the buyer’s perspective. A good pricing model is good for both the buyer and seller. This is not a zero-sum game.
In fact, one should assess the pricing model for each combination of Use Case x Ideal Customer Profile. A pricing model that works well for one type of customer for one use case will not always work well for a different customer or use case. One ends up with a matrix that shows how well the pricing model performs in different contexts.
These assessments can be made using public information (as we do below) or they can be enriched by using proprietary vendor data.
Each factor is assessed on a 0 to 5 scale (we are testing more fine-grained scales). We include a ‘zero’ because some of the scoring algorithms are multiplicative, and if there is a zero, then the score on that factor goes to zero.
Let’s look at an example.
Benchmarking Intercom Fin.ai pricing
Intercom’s Fin.ai pricing model has become an iconic early example of outcome based pricing for an AI agent. See AI applications edge toward outcome based pricing.
How does it perform when assessed against the twelve factors? (We are keeping the prompts used confidential as we will be testing this framework against some 50 pricing models over the next few weeks.)
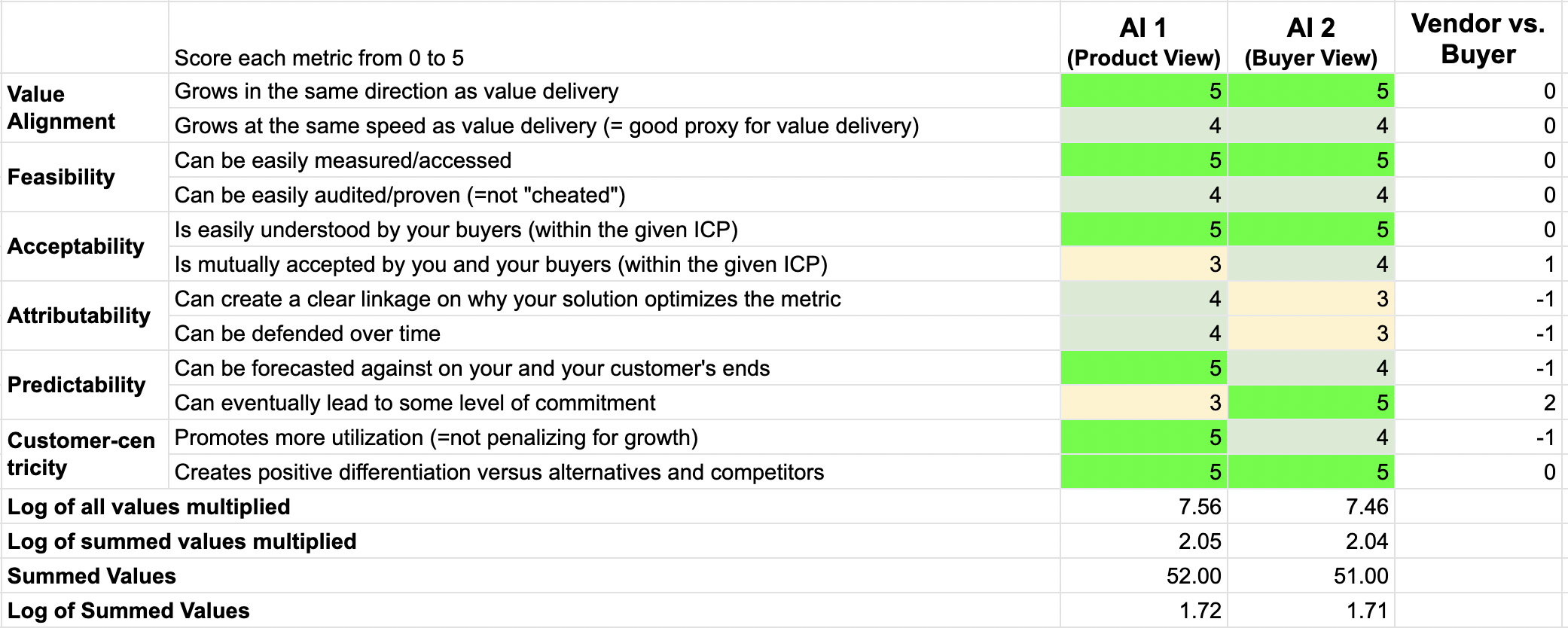
Assessment of Intercom’s FinAI pricing model, conducted May 29, 2025 using the 12-factor pricing model benchmark.
The full report (available to people participating in our research, see below) provides the reasoning behind each score.
This is one of the better-performing models we have assessed, and it is quite well balanced from both the vendor and buyer perspectives. The difference between the two scores is minimal across all of the scoring algorithms. It is not perfect, though, and there is room for improvement in Acceptability and Predictability.
Part of our research will investigate how stable these scores are. Will they change over time as market conditions change and other vendors innovate on their pricing models?
Invitation to Participate in Pricing Benchmarking Research
If you are interested in contributing to this research, please reach out to info@ibbaka.com. We will benchmark your pricing model with you and discuss the results. We can also benchmark your competitors’ pricing models to see how you compare. We plan to add pricing model benchmarking to our category value reports.
