How a role and skill model evolves


Steven Forth is co-founder and managing partner at Ibbaka. See his skill profile here.
Competency models need to evolve. The world we work in is too fluid for rigid frameworks. Changes in growth models, organization design and technologies are opening up new roles and ways of working together. At the same time, the skills used in existing roles continue to evolve. Skills that were once seen as unique become table stakes, and new skills emerge for well established roles.
How do you collect and use data about skills? Please share your thoughts.
What is it that evolves in the skill and role model?
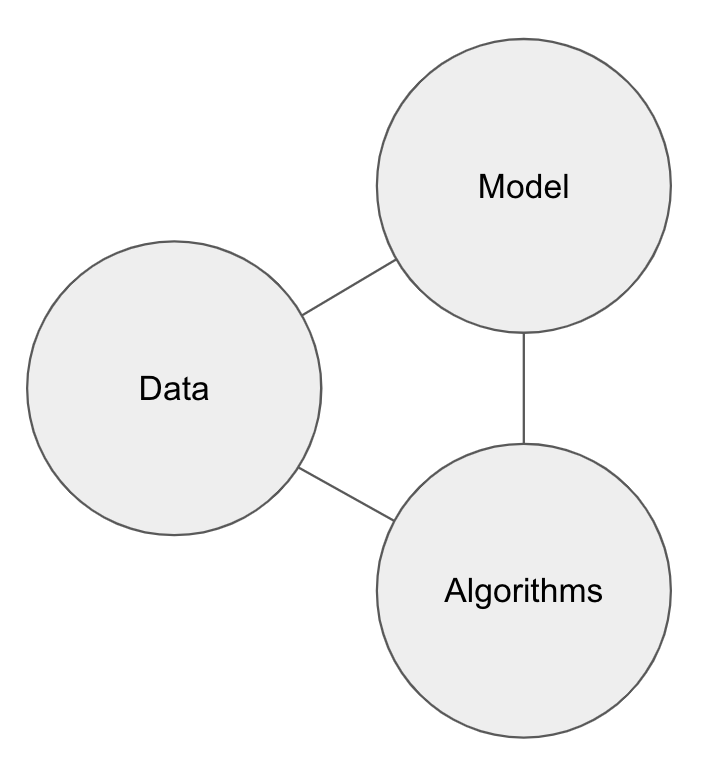
There are three things that change over time.
The data in the model
The model used to organize the data
The algorithms used to win insights from the combination of model and data
Let’s look at each of these.
The data in the role and skill model
What is data, what is model? In fact there can be a grey area here. For Ibbaka the data is the skill graph.
The skill graph is a data structure that represents how skills are connected to other skills. The skills are the nodes or vertices in the graph and the connections are the lines or edges connecting the skills. There can be different types of connections. For example, Ibbaka puts skills in categories (in this case the category name is also a node and there is an edge connecting every skill in the category to the node for the category. Other types of edges are associated, complementary and connecting skills. See Core Concepts: Complementary, Associated and Connecting Skills.
Skill graphs often contain nodes other than skills. An example, given above, is categories. Other nodes often found in skill graphs are Jobs, Roles, Behaviours, Experiences, Activities, Tasks, Responsibilities, Goals, Outcomes, Teams, Projects. If you can use a concept in a Job Architecture or Competency Model, it can also show up in a skill graph.
From “Core Concepts; Skill Graph”
The skill graph changes every time someone adds a skill, uses a skill in a role or on a project, or connects to another person through a skill. It is a sprawling, changing information set with many nodes and edges.
The model used to define roles, behaviours, skills
There are many ways one could organize the skill graph. One way to organize the graph is through a competency model. These models are used to organize the skills needed to perform work. The Ibbaka platform supports many different ways to organize these models but after much experience our most common architecture is as follows:
Job
Role
Activities
Skills
We also append Credentials and Learning Resources to each of these levels.
Depending on how the model will be used we sometimes use Values, Behaviours or Tasks. And we sometimes differentiate between Job Roles (roles that are part of a job), team roles and ad-hoc roles (‘I am doing this off the side of my desk’).
One common use of these models is in Role Coverage and Skill Gap analysis, where we ask if an organization has people in the right roles and if those people have the needed skills.
These models can also be used to design learning curriculums or to plan career paths. Teams can have their own custom competency model, tuned to their needs.
Some of us even have our own personal competency models to describe how we approach our own work.
The algorithms used to win insights from the combination of model and data
So there is data (the skill graph) and a model to organize the data. This is still not enough. One needs to generate insights from the interaction of the model and data. At Ibbaka we do this with a set of algorithms. ‘Algorithm’ is really just a fancy work for a set of instructions that is specific enough for a computer to follow. There are a lot of algorithms at play here.
SkillRank is the algorithm Ibbaka uses to estimate the level of expertise a person has on a skill. See Core Concepts: SkillRank
RoleMatch is the algorithm used to judge how well a person matches a specific role, for a job or on a team
The Skill/Role Insights algorithms aggregate and summarize skill/role information with respect to a specific model together with a specific group of people
Other algorithms are being developed.
These algorithms are not set in stone, they are designed to evolve as the system learns. What does it mean to talk about the system learning?
Roles, skills and single loop learning
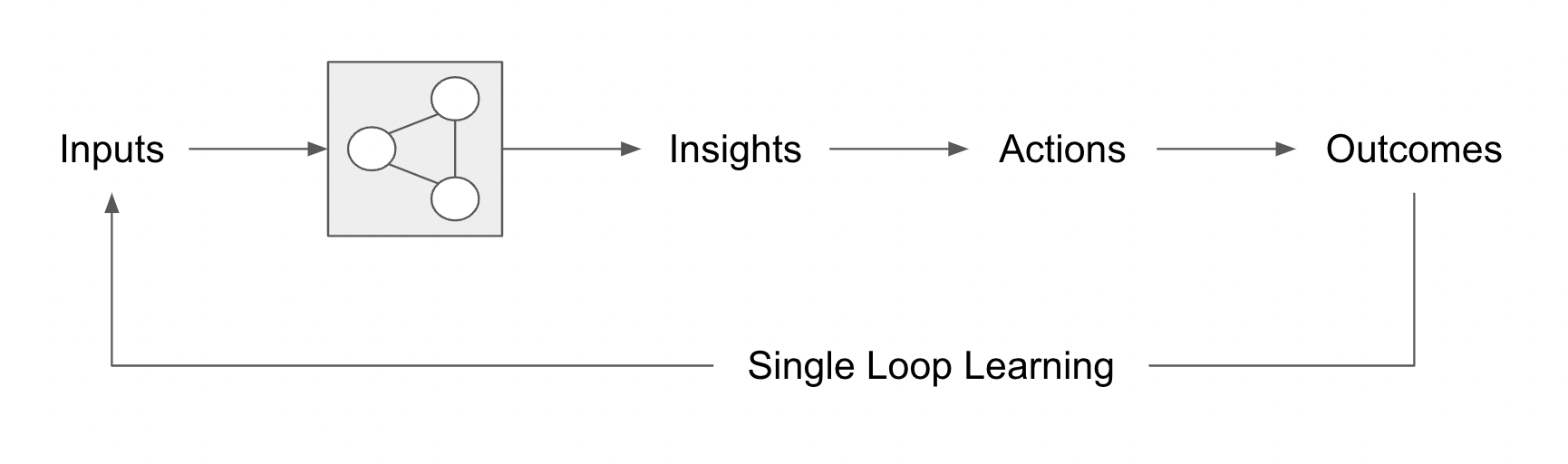
Organizational and learning design expert Chris Argyris proposed two models of learning, single loop learning and double loop learning.
Beginning with single loop learning, the loop is created by having Insights lead to Actions that have Outcomes. The Outcomes can themselves become inputs into the system (changes to the skill graph) or they can trigger inputs such as updating of skill data or a new skill survey.
The key to enabling single loop learning is to make sure that the Outcomes trigger new Inputs. What kinds of outcomes are we talking about here?
Goal achievement by individuals, teams and the organization as a whole
Role performance for a job role or a team role
Skill growth through increasing levels of expertise or the incorporation of new skills
Role coverage, as an outcome of skill growth, hires, outsourcing or role sharing
From single loop learning to double loop learning in role coverage and skill gap analysis

For Chris Argyris single loop learning was not enough to transform an organization. For that one needs double loop learning. In double loop learning the interactions between the data (skill graph), model and algorithms evolve. Practically, this generally means explicit changes to competency model and to the algorithms generating the insights.
At present, at least for Ibbaka, this is an iterative design process. After each turn around the Inputs to Outcomes and back to Inputs loop we pause to reflect, and look at how the model and the algorithms could be changed to deliver better outcomes.
A new role may be needed, or perhaps two roles can be combined. Skills can be pruned out or new skills added. The algorithms can be rewritten or rebalanced.
We can measure our progress as the whole system is a Bayesian network, measuring our confidence in the algorithms prediction as well as the prediction itself.
In the future, we hope to make the models and algorithms directly adaptive, such that the algorithms and skill graph interact to change the model, and the algorithms use deep learning to improve their ability to predict outcomes.
Double loop learning is the key to personal and organizational performance
Our goal at Ibabka is to enable double loop learning at your organization. This is an ambitious goal. We work with individuals and companies that share our passion for adaptive learning that can deliver results in a changing environment.
